(无花果 和 gemini 2.5pro 共同制作) -- 其实 2.5pro是主笔 嘻嘻
这篇论文,主要探讨了在存在试图操纵排名的“虚假用户”时,如何为在线平台创建可靠的产品排名系统。
核心问题:
在线平台严重依赖产品排名来引导顾客,因为用户通常只看排名靠前的商品 。这些平台通过观察顾客行为(如点击)来学习如何对产品进行排名 。然而,这也促使卖家雇佣虚假用户(例如,通过点击农场)来人为地提升其产品的排名 。这种欺诈行为可能导致次优排名,从而对真实用户的体验和平台的效率产生负面影响 。该论文要解决的核心问题是:在线平台在存在难以区分的虚假用户的情况下,能否有效地学习到最优的产品排名?
现有算法的不足:
作者指出,常见的学习算法,例如基于“置信区间上界”(Upper Confidence Bound, UCB)的算法,在没有虚假用户时表现最优,但在被操纵时性能可能非常差 。这些算法可能会收敛到非常糟糕的排名,并且即使只有少量虚假用户,其“遗憾”(regret,衡量算法性能的指标)也会随时间线性增长(Ω(T)) 。这种脆弱性源于算法对早期估计的依赖,以及由于用户顺序搜索行为导致难以获得低排名产品反馈的困境 。
UCB 算法 - 复习
UCB 算法是一种经典的解决“多臂老虎机问题”(Multi-Armed Bandit Problem)的策略。想象一下,您面前有多台老虎机(“臂”),每台老虎机以不同的、未知的概率吐出奖励。您的目标是在有限的尝试次数内,最大化您获得的总奖励。

UCB 算法的核心思想
UCB 算法试图在 “探索”(Exploration) 和 “利用”(Exploitation) 之间取得平衡。
- 利用 (Exploitation):选择目前为止表现最好的老虎机,也就是平均奖励最高的老虎机。这能让您在短期内获得较多奖励。
- 探索 (Exploration):尝试那些您不太了解或者尝试次数较少的老虎机。虽然短期内可能奖励不高,但您可能会发现一个实际上更好的老虎机。
UCB 算法通过为每个“臂”(在论文中对应每个“产品”或“排名”)计算一个置信区间上界值来实现这种平衡。在每一轮,算法会选择这个上界值最高的臂。

UCB 值的计算
这个上界值通常由两部分组成 :
- 经验平均奖励 (Empirical Mean Reward):这是该臂到目前为止的平均奖励,代表了“利用”的程度 。
- 置信区间宽度/探索项 (Confidence Interval Width / Exploration Term):这个值会随着该臂被选择的次数增加而减小 。如果一个臂被选择的次数很少,那么它的置信区间会比较宽,探索项的值就比较大,使得这个臂有更高的机会被选中,这就是“探索”。
具体的计算公式在论文中被简化为:
$UCB_i = \hat{\mu_i} + \sqrt{\frac{\log T}{\eta_i}}$
其中:
- $UCB_i$ 是第 i 个臂的置信区间上界值。
- $\hat{\mu_i}$ 是第 i 个臂的经验平均奖励(例如,产品的平均点击概率)。
- $T$ 是总的尝试轮数(时间范围)。
- $\eta_i$ 是第 i 个臂到目前为止被选择(或观察到反馈)的次数。
在论文的讨论中,研究者指出,传统的基于 UCB 的排名算法(如 CascadeUCB)在面对虚假用户时表现不佳。虚假用户可以通过操纵点击,使得 UCB 算法错误地估计产品的吸引力,从而导致算法收敛到次优的排名,并产生线性增长的遗憾 。例如,虚假用户可以通过在早期不点击任何产品,然后在特定时间段内集中点击某个次优产品,来欺骗 UCB 算法高估这个次优产品的价值,同时低估优质产品的价值 。
提出的解决方案:
为解决这一问题,研究人员开发了两种新的学习算法,旨在抵抗虚假用户,这两种算法在对“虚假预算”(F,虚假用户行为的总数)的了解程度上有所不同。
1. 知晓虚假预算的排名算法 (Fake-Aware Ranking, FAR):


-
该算法适用于平台能够估计虚假预算 F 的场景 。
-
FAR 使用“产品排序图”来追踪产品之间的两两关系。图中从产品 j 到 i 的一条边意味着产品 i 可能优于产品 j 。
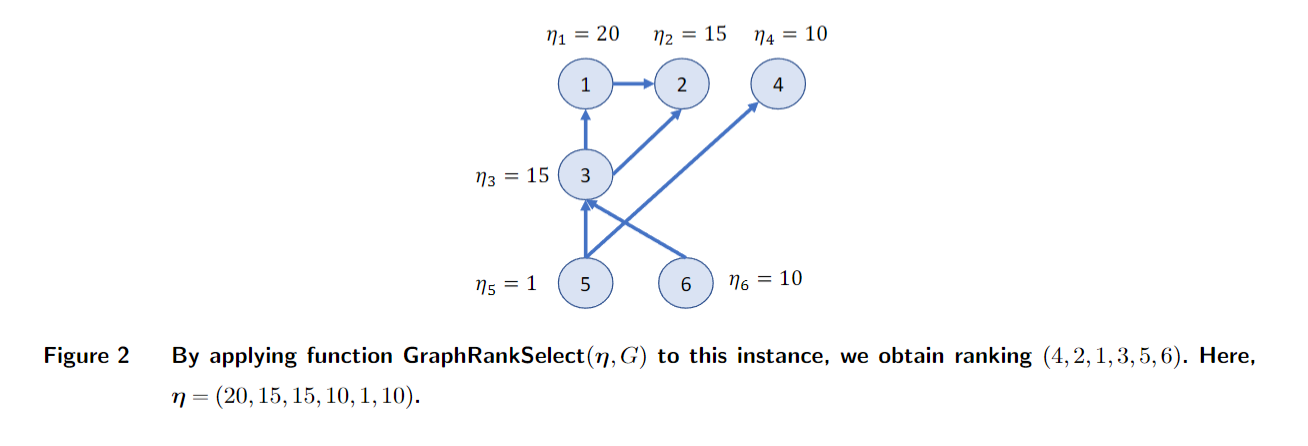
-
它通过扩大与产品点击率估计相关的置信区间来保守地向图中添加边,额外的宽度与 F 成正比,以抵消虚假用户造成的扭曲 。
-
排名决策优先考虑图中没有出边(意味着它们可能优于其余产品)的产品,并通过优先选择反馈计数较少的产品来打破平局,以鼓励探索 。
-
FAR 实现的最坏情况遗憾为 O(log(T) + F) 。
2. 不知晓虚假预算的跨学习排名算法 (Fake-Oblivious Ranking with Cross-Learning, FORC):

-
这种更具创新性的算法适用于平台_不_知道虚假预算 F 的情况 。
-
FORC 采用多层次随机方案,并行运行 L ≈ log₂(T) 个学习层级 。
-
每个层级都有自己的产品排序图。较高层级被抽样的频率较低(l 层级的概率与 2⁻ˡ 成正比),因此接触到的虚假用户较少,学习更准确但较慢 。较低层级学习较快,但更容易受到操纵 。
-
FORC 有效性的关键在于层级之间的双向跨学习:
-
向下跨学习: 在较高、更鲁棒的层级推断出的准确产品两两关系会立即传递到所有较低层级 。如果这在较低层级的图中产生循环(矛盾),则该图将被消除 。
-
向上跨学习: 在较低层级收集的顾客反馈会部分用于较高层级的产品比较,从而能够在这些保守的层级更快地推断出准确的关系 。
-
-
FORC 实现的最坏情况遗憾为 O(F log(T)) 。
核心方法论贡献:
-
产品排序图: 这些图编码了推断出的产品两两关系,指导排名过程 。
-
带有双向跨学习的多层学习: FORC 中的这种方法允许算法即使在不知道虚假用户活动程度的情况下也能保持鲁棒性,通过在不同层级分散和减轻损害,并利用层级之间的信息流 。
基础模型:
-
平台展示
n个点击概率(μᵢ)未知的产品 。理想情况下,产品应按这些概率的降序排列 。 -
顾客搜索(级联模型): 真实顾客从顶部开始顺序检查产品 。他们以产品的点击概率点击可接受的产品,然后停止 。如果他们不点击,他们可能会(以与位置相关的概率)退出,或检查下一个产品 。
-
虚假用户: 他们的行为不受约束;他们可以策略性地点击或不点击以操纵排名,总行为次数不超过虚假预算 F 。平台无法将他们与真实用户区分开来 。
-
平台目标与遗憾: 平台旨在找到能够最大化_真实_顾客点击量的排名 。性能通过累积遗憾来衡量:即在 T 个回合中,最优排名与算法排名之间的预期奖励差异 。遗憾的定义侧重于真实顾客的参与度,因为虚假点击不提供实际价值 。
数值研究:
-
合成数据的模拟证实,类似 UCB 的算法确实很脆弱,会产生线性遗憾 。
-
FAR 和 FORC 都表现出次线性的遗憾 。
-
令人惊讶的是,FORC 尽管不知道虚假预算,但其性能优于 FAR 。这突显了其多层学习和跨学习机制在实现鲁棒性能方面的强大作用 。研究表明,FORC 的层级如何演变,较低层级最初受到误导,然后通过跨学习被较高层级纠正,从而消除被污染的图并收敛到最优排名 。
结论与启示:
论文的结论是,在线平台可以通过设计新的学习算法来有效打击欺诈用户 。结果表明,即使平台完全不知道虚假用户的数量和身份,也有可能有效地收敛到最优产品排名 。这项工作为设计鲁棒系统提供了见解,包括保守推断、使用并行化和随机化,以及采用跨学习等机制 。这项研究是最早强调卖家如何通过虚假用户利用位置偏差,并为此提供了建设性解决方案的工作之一 。

此处评论已关闭