created: 2025-05-26 tags:
- 程序设计
- 并行
课件: 【金山文档 | WPS云文档】 Lec08-MPI
集合通信只支持组内通信
按照通信方向的不同,又可以分为三种:
- 一对多通信:一个进程向其它 所有 的进程发送消息,这个负责发送消息的进程叫做Root进程。
- 多对一通信:一个进程从其它 所有 的进程接收消息,这个接收的进程也叫做Root进程。
- 多对多通信:每个 进程都向 其它所有 的进程发送或者接收消息。

MPI_Bcast
广播是一对多通信的典型例子,其调用格式如下:
MPI_Bcast(Address, Count, Datatype, Root, Comm)
三元组 (Address, Count, Datatype) + Root 根进程 + Communicator 通信域
- Root 向通信域内所有进程发送消息

MPI_Gather
MPI_Gather(SendAddress, SendCount, SendDatatype, RecvAddress, RecvCount, RecvDatatype, Root, Comm)
接收缓冲由三元组
<RecvAddress, RecvCount, RecvDatatype>标识,发送缓冲由三元组<SendAddress, SendCount, SendDatatype>标识,所有非Root进程忽略接收缓冲

SendCount 和 RecvCount可以不一致吗?
解答: 不可以
全局收集 MPI_Allgather : 所有进程都是 Root
MPI_Allgather(SendAddress, SendCount, SendDatatype, RecvAddress, RecvCount, RecvDatatype, Comm)

我想把程序贴上来 , 但是地方太小了 ...
路径: /Volumes/orico/Programming/Parallel/MPI集合通信/MPI_Allgather.c
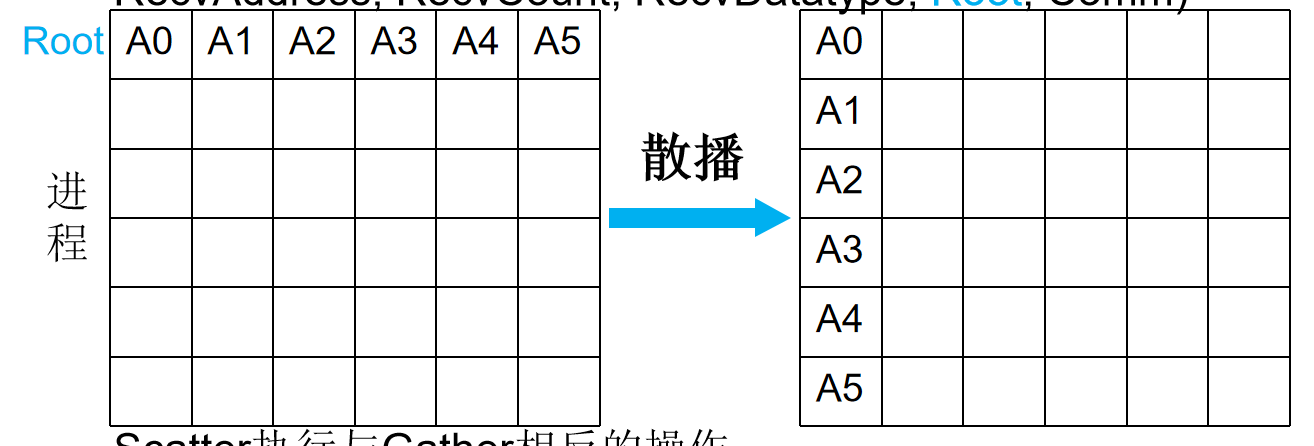
散播 MPI_Scatter
MPI_Scatter(SendAddress, SendCount, SendDatatype, RecvAddress, RecvCount, RecvDatatype, Root, Comm)
Scatter执行与Gather相反的操作
地址: /Volumes/orico/Programming/Parallel/MPI集合通信/MPI_Scatter.c
数据分发的规则
- 根进程(rank 为
root的进程)将sendbuf中的数据按照进程编号(rank)顺序分发。 - 数据被分成
comm中进程数量的份,每份的大小为sendcount * sizeof(sendtype)。 - 进程 0 接收
sendbuf中的前sendcount个元素,进程 1 接收接下来的sendcount个元素,依此类推。 - 每个进程(包括根进程)都会将接收到的数据存储到自己的
recvbuf中。

但是:`MPI_Scatter` 是并行的,数据分发不是按进程编号串行发送,而是尽可能同时向所有进程发送。具体实现依赖于 MPI 库和底层网络,但设计目标是并行分发以提高效率。
全局交换 MPI_Alltoall
每个进程把自己的消息n等分,按照进程号发送给所有进程(包括自己) 其中一份
- 可以视作 : 每个进程都视为Root的MPI_Scatter

路障 MPI_Barrier
- 同步功能用来协调各个进程之间的进度和步伐 。目前MPI的实现中支持一个同步操作,即路障同步(Barrier)。
路障同步的调用格式如下:
MPI_Barrier(Comm)
- 在路障同步操作MPI_Barrier(Comm)中,通信域Comm中的 所有进程相互同步。
- 在该操作调用返回后,可以保证组内所有的进程都已经执行完了调用之前的所有操作,可以开始该调用后的操作。
聚合操作: 归约和扫描
集合通信的聚合功能使得MPI进行通信的同时完成一定的计算。
MPI聚合的功能分三步实现:
- 首先是通信的功能,即消息根据要求 发送到目标进程,目标进程也已经收到了各自需要的消息;
- 然后是对消息的处理,即执行计算功能;
- 最后把处理结果放入指定的 接收缓冲区。
- MPI提供了两种类型的聚合操作: 归约和扫描。
MPI_Reduce(SendAddress, RecvAddress, Count, Datatype, Op, Root, Comm)

- Allreduce : 也就是所有的进程都视为根进程 , 执行一次
预定义的归约操作:

用户自定义的归约操作
int MPI_Op_create(
//用户自定义归约函数
MPI_User_function *function,
// if (commute==true) Op是可交换且可结合
// else 按进程号升序进行Op操作
int commute,
MPI_Op *op
)
用户自定义的归约操作函数须有如下形式:
typedef void MPI_User_function(
void *invec,
void *inoutvec,
int *len, //从MPI_Reduce调用中传入的count
MPI_Datatype *datatype);
函数语义如下:
for(i=0;i<*len;i++) {
*inoutvec = *invec USER_OP *inouvec;
inoutvec++; invec++;
}
示例: 复数乘法
typedef struct {
double real,imag;
} Complex;
/* the user-defined function */
void myProd( Complex *in, Complex *inout, int *len, MPI_Datatype *dptr )
{ int i;
Complex c;
for (i=0; i< *len; ++i) {
//交叉乘
c.real = inout->real*in->real - inout->imag*in->imag;
c.imag = inout->real*in->imag + inout->imag*in->real;
*inout = c;
in++; inout++;
}
/* explain to MPI how type Complex is defined */
MPI_Type_contiguous( 2, MPI_DOUBLE, &ctype );
MPI_Type_commit( &ctype ); //提交我们刚刚创建的数据类型
/* create the complex-product user-op */
MPI_Op_create( myProd,1, &myOp );
MPI_Reduce( a, answer, LEN, ctype, myOp, 0, MPI_COMM_WORLD );
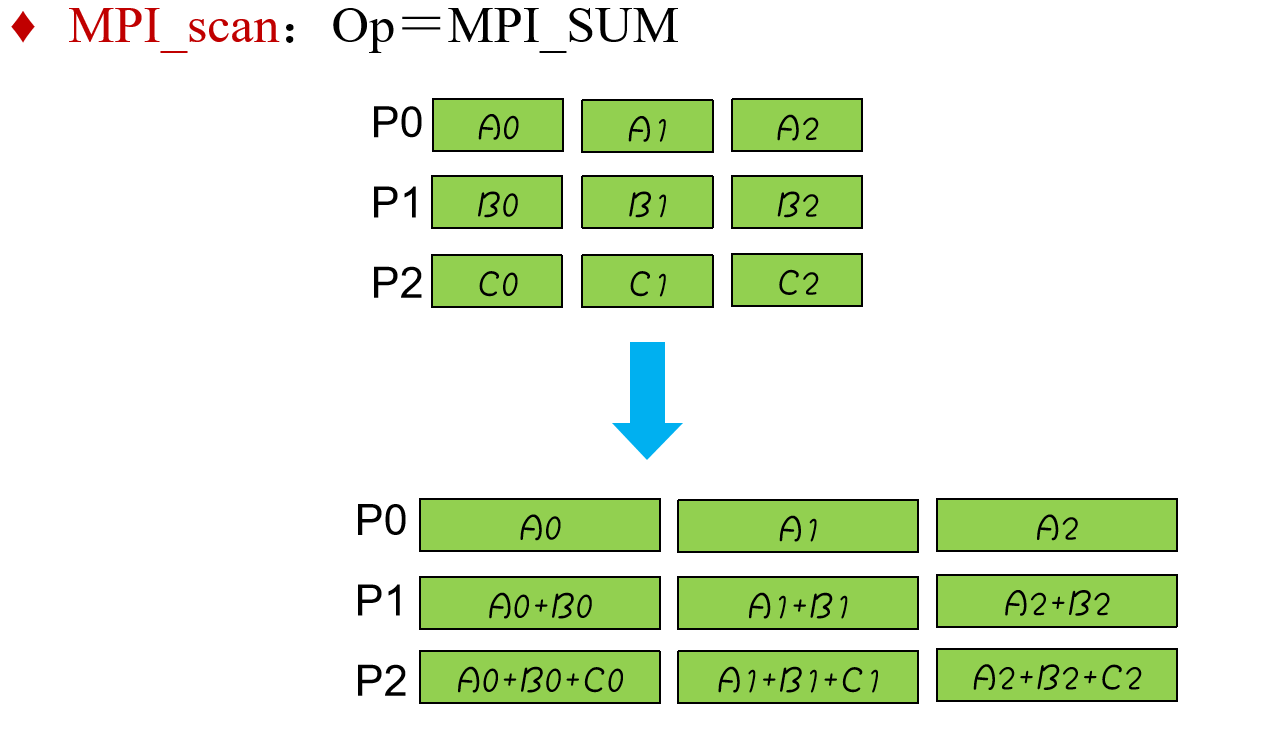
MPI_scan 扫描
MPI_scan(SendAddress, RecvAddress, Count, Datatype, Op, Comm)
可以把扫描操作看作是一种特殊的归约(Reduction),即每一个进程都对 ***排在它前面(包括自己)*** 的进程进行归约操作。
允许每个进程贡献向量值,而不只是标量值。向量的长度由Count定义。
集合通信 特点
- 通信域中的所有进程必须调用群集通信函数。如果只有通信域中的一部分成员调用了群集通信函数而其它没有调用,则是错误的。
- 除
MPI_Barrier以外,每个群集通信函数使用类似于点对点通信中的标准、阻塞的通信模式。也就是说,一个进程一旦结束了它所参与的群集操作就从群集函数中返回,但是并不保证其它进程执行该群集函数已经完成。 - 一个群集通信操作是不是同步操作取决于实现。MPI要求用户负责保证他的代码无论实现是否同步都必须是正确的。
- 所有参与群集操作的进程中,
Count和Datatype必须是兼容的。 - 群集通信中的消息没有 消息标签参数,消息信封由通信域和源/目标定义。例如在
MPI_Bcast中,消息的源是Root进程,而目标是所有进程(包括Root)。
为什么没有消息标签: 因为要求所有成员都参与;
案例
梯形积分法
分成非常多个小梯形, 平均分成给n个进程 ; Sum up 即可
操作和 Reduce 通信模式是一致的 , 可以用集合通信 (归约);
- 当然,我们也可以通过点对点通信 , 传给 0 号进程求和 & 打印.
集合通信不需要按照语序顺序, 速度更快
奇偶排序
冒泡排序的改进版本
- 内容有点多, 这里不写了; 可以看看 PPT
MPI_PROC_NULL : 调用后直接返回 (没有
partner)
MPI 程序的安全性问题
- 使用标准通信模式 的 MPI_Send 函数进行通信
- 相对较小的消息由MPI设置的缓冲区并返回;
- 相对较大的消息 => 直到对应的
MPI_Recv出现前都阻塞
若每个进程都阻塞在MPI_Send上 , 就会发生死锁或者挂起
环形传递问题
- 解决方案: 用
MPI_Sendrecv代替 , 系统会根据环境适当打断通信 ; 避免死锁

此处评论已关闭